Chapter 8 Categorical variables and logistic regression
In previous weeks, we ventured into the world of bivariate analysis and even multivariate analysis. We learned that we always have a dependent variable (aka outcome or response variable), which measures the phenomenon we aim to explain, and one or more independent variables (aka explanatory or predictor variables), which represent the phenomena we think explain that.
We essentially learned how to handle every possible scenario when the dependent variable is numerical. For instance, if the independent variable is binary, we are interested in the mean difference—i.e., the extent to which the average score of the dependent variable is different in one group in relation to the other group. If the independent variable is categorical with more than two groups, we are interested in the extent to which average scores of the dependent variable are different in each of the groups in relation to a reference group. If the independent variable is numerical, we are interested in the extent to which average scores of the dependent variable are expected to change based on every one-unit increase in the independent variable. In all these cases, we saw that the linear regression model provides a powerful framework for quantifying these relationships. In every scenario, the slope coefficient represents the association between any independent variable and a numerical variable.
Now, however powerful and versatile linear regression models are, they rely on a key assumption: the dependent variable must be numerical. Models are very flexible as to what can go into the right-hand side of the linear equation, but the left-hand side is pretty restrictive. So, what do we do when we have a categorical dependent variable? That’s our focus this week! This week is all about categorical variables. We begin by introducing a common method for describing relationships between any two categorical variables: cross-tabulations. We then move on and learn about a new type of regression model—one that is very similar to everything we already know about linear regression models but designed to accommodate binary dependent variables: logistic regression models.
8.1 Cross-tabulations
In earlier sessions, we covered how to run frequency distributions using the table() function. Cross tabulations, also called contingency tables, are essentially crossed frequency distributions, where you plot the frequency distributions of more than one categorical variable simultaneously. This semester, we are only going to explore two-way cross-tabulations, that is, contingency tables where we plot the frequency distribution of two categorical variables at the same time. Frequency distributions are a useful way of exploring categorical variables that do not have too many categories. By extension, cross-tabulations are a useful way of exploring relationships between two categorical variables that do not have too many levels or categories.
This week, we will use the Arrests dataset from the effects package. You can obtain details about this dataset and the variables included by using help(Arrests, package="effects"). If you don’t have that package, you must install and load it.
# install package if you haven't done so
## install.packages("effects")
# load the 'effects' package
library(effects)
# load the dataset "Arrests"
data(Arrests)#, package = "effects")Please note that when importing data into R using the data() function, the imported object may not immediately appear in the Environment panel. Worry not—if you didn’t receive any error messages, the data frame Arrests (note the capitalised letter!) should be loaded into your R session. To double-check, let’s check the dimensions of this data frame.
## [1] 5226 8We can see that the data frame Arrests has 5226 observations and 8 columns. The unit of analysis here is individuals arrested in Toronto for possession of marijuana. For each of these 5226 individuals, we have information on eight characteristics. Let’s check the names of the variables.
## [1] "released" "colour" "year" "age" "sex" "employed" "citizen"
## [8] "checks"This dataset includes information on police treatment of individuals arrested in Toronto for possession of marijuana. For example, it includes information on whether they are White or Black (colour), the year (year), their age (age), their gender (sex), whether they are currently employed (employed), whether they are Canadian citizens (citizen), and the number of entries in the criminal justice system (checks). Crucially, the dataset also contains information indicating whether the arrestee was released with a summons. In this case, the police could:
Release the arrestee with a summons—like a parking ticket
Bring to the police station, held for bail, etc.—harsher treatment
Let’s use the table() function to examine the frequency distribution of this variable
##
## No Yes
## 892 43344334 arrestees were released with a summons, whereas 892 received a harsher treatment. As usual, when dealing with frequency tables, it is often better to examine results in relation to proportions (or percentages) instead of raw counts. We can obtain proportions using the prop.table() function (do note that the prop.table() function requires a table() object as its argument!).
# store the frequency table under the name "table_released"
table_released <- table(Arrests$released)
# compute proportions of the frequency table
prop.table(table_released)##
## No Yes
## 0.170685 0.829315In other words, 82.93% of arrestees were released with a summons, and 17.07% received a harsher treatment. Let’s see if we can develop an understanding of the factors that affect this outcome. In particular, let’s assume our research goal is to investigate whether race is associated with harsher treatment. In this case, race is our independent variable, and the treatment offered to the arrestees is our dependent variable.
Let’s quickly examine our independent variable too.
# store the frequency table under the name "table_colour"
table_colour <- table(Arrests$colour)
# print the frequency table
table_colour##
## Black White
## 1288 3938##
## Black White
## 0.24646 0.75354Now we know that our sample contains 1288 (24.65%) Black arrestees and 3938 (75.35%) White arrestees.
Given that they are both categorical variables, we can start producing a cross-tabulation. We can simply use the table() function and another variable as a second argument in the function. The first variable included in the function will be represented by rows, whereas the second variable will be represented by columns. Conventionally, we usually include the dependent variable in the columns and the independent variable in the rows
# produce a cross-tabulation and store it under "crosstab_released"
crosstab_released <- table(Arrests$colour, Arrests$released)
# print the cross-tabulation
crosstab_released##
## No Yes
## Black 333 955
## White 559 3379By checking both frequency distributions at the same time, we can see that 333 arrestees are Black and received a harsher treatment, 955 are Black and were released with a summons, 559 are White and received a harsher treatment, and 3379 are White and were released with a summons. So, is there an association? Do we think that Black arrestees are treated more harshly than White arrestees?
As before, just looking at the raw counts is tricky. A better approach is to look at proportions. But which proportions? If we simply use the prop.table() function, R will calculate the total percentages—but that is not very helpful in addressing our question.
##
## No Yes
## Black 0.06371986 0.18274015
## White 0.10696517 0.64657482We can see now that 6.37% of all arrestees are Black and received a harsher treatment, 18.27% are Black and were released with a summons, 10.7% are White and received a harsher treatment, and 64.66% are White and were released with a summons. In other words, what the prop.table() function did was just divide the raw count in each cell of the contingency table by the total number of arrestees in the dataset (i.e., 5226). Not very helpful.
Instead, we are only interested in the proportions that allow us to make meaningful comparisons. We already knew that Black arrestees were only 24.65% of our sample, so calculating total percentages does not seem to be very useful. Aside from total percentages, we can also compute row percentages and column percentages. For example, among only Black arrestees, what is the percentage that received a harsher treatment? What about among only White respondents? This is the idea of marginal frequencies and percentages!
Given that we always have an independent variable doing the explanation and a dependent variable being explained, we only need percentages that allow us to make comparisons for the dependent variable across our independent variable. In this case, we want to examine percentages of police treatment across groups of racial identity. In other words, because we conventionally display the dependent variable in the columns and the independent variable in the rows, we only want to request row percentages. We can request row percentages by adding the argument margin = 1 into the prop.table() function:
##
## No Yes
## Black 0.2585404 0.7414596
## White 0.1419502 0.8580498What this argument does is calculate proportions one row at a time. Among Black arrestees only, 25.85% received a harsher treatment and 74.15% were released with a summons. Among White respondents only, 14.2% received a harsher treatment and 85.8% were received with a summons. Now, comparisons are easier to make! We can see that Black arrestees seem to be more likely to receive a harsher treatment than White arrestees (i.e., 25.85% vs. 14.2%); accordingly, White respondents are more likely to be released with a summons than Black respondents (i.e., 85.8% vs. 74.15%).
Attention! What about column percentages?
We can also request column percentages by specifying margin = 2 in the prop.table() function.
##
## No Yes
## Black 0.3733184 0.2203507
## White 0.6266816 0.7796493For example, among all arrestees who received a harsher treatment, 37.33% are Black and 62.67% are White. Among all arrestees who were released with a summons, 62.67% are Black and 77.96% are White.
This is of less substantial interest to us, as we are typically interested in assessing the distribution of the dependent variable across groups of the independent variable. If you include your independent variable in the columns (which is not conventional), then you might want to compute column percentages. Pay very close attention to this. It is a very common mistake to interpret a crosstab the wrong way if you don’t do it as explained here.
To reiterate, there are two rules for producing and reading cross tabs the right way. The first rule for reading cross-tabulations is that ** if your dependent variable defines the columns (as seen here), then you would need to ask for the row percentages. If, on the other hand, you decided that you preferred to have your dependent variable defining the rows, then you ask for the column percentages.**. Make sure you remember this.
While the table() and prop.table() functions do everything we need, some other functions in R allow a better-formatted inspection of cross-tabulations. For example, the tbl_cross() function from the gtsummary package provides a neat table with all the information we need. This is how it works.
# template for the tbl_cross() function
tbl_cross(data = mydataset, row = independent_variable, col = dependent_variable, percent = "row")In our case, we can now use the tbl_cross() function to produce a neat cross-tabulation!
# remember to install the 'gtsummary' package
## install.packages("gtsummary")
# load the 'gtsummary' package
library(gtsummary)
# produce a neatly formatted cross-tabulation
tbl_cross(data = Arrests, row = colour, col = released, percent = "row")|
released
|
Total | ||
|---|---|---|---|
| No | Yes | ||
| colour | |||
| Black | 333 (26%) | 955 (74%) | 1,288 (100%) |
| White | 559 (14%) | 3,379 (86%) | 3,938 (100%) |
| Total | 892 (17%) | 4,334 (83%) | 5,226 (100%) |
It’s the same information but much better! Much less cluttered. We can see the frequency distribution and the marginal frequencies—i.e., totals by rows and columns which appear along the right and the bottom. We can also see the row percentages, which allows us to conclude that Black arrestees tend to receive a harsher treatment than White arrestees.
This can sound a bit confusing now. But as long as you remember, your dependent should always define the columns, and therefore, you should ask for the row percentages, and you should be fine. There are always students who get this wrong in the assignments and lose points as a result. Don’t let it be you.
The second rule for reading cross-tabulations the right way is this: You make the comparisons across the right percentages in the direction where they do not add up to a hundred. Another way of saying this is that you compare the percentages for each level of your dependent variable across the levels of your independent variable. In this case, we would, for example, compare the police decision to release arrestees with a summons or take them to the station. Looking at the first column only—arrestees who were not released, i.e., who received a harsher treatment—we can see that Black individuals are 26% and White individuals are 14%. Looking at the second column only—arrestees who were released with a summons—we can see that Black individuals are 74% and White individuals are 86%.
Your turn! Using cross-tabulations, what do you conclude about the association between the following variables:
- Do arrestees with a citizenship status tend to receive harsher treatment by the police?
Reveal answer!
In this case, police treatment is our dependent variable. We operationalise it using the released variable, which indicates whether arrestees were released with a summons or received harsher treatment. Citizenship status is our independent variable, and the variable citizen indicates whether arrestees are Canadian citizens or not. Given that they are both categorical (binary) variables, we produce a cross-tabulation to assess whether they are associated.
We know that 17.07% arrestees received a harsher treatment and 82.93% were released with a summons. If citizenship status is not associated with police treatment (i.e., if the null hypothesis is true), we should expect roughly similar proportions among both citizens and non-citizens. If, however, proportions across citizens and non-citizens are different, that would serve as evidence that the two variables could be associated.
Let’s have a look at the cross-tabulation.
# produce a cross-tabulation between 'citizen' and 'released'
tbl_cross(data = Arrests, row = citizen, col = released, percent = "row")|
released
|
Total | ||
|---|---|---|---|
| No | Yes | ||
| citizen | |||
| No | 212 (27%) | 559 (73%) | 771 (100%) |
| Yes | 680 (15%) | 3,775 (85%) | 4,455 (100%) |
| Total | 892 (17%) | 4,334 (83%) | 5,226 (100%) |
The table indicates that, while only 15% of arrestees received harsher treatment among citizens, 27% of arrestees without citizenship status had the same decision. Similarly, while 85% of those with citizenship status were released with a summons, only 73% of those without citizenship status were released. This suggests that citizenship status seems to be associated with police treatment, as non-citizen individuals appear to be more likely to receive harsher treatment.
- Do male arrestees tend to receive harsher treatment by the police?
Reveal answer!
In this case, arrestees’ gender is our independent variable, and the variable sex indicates whether arrestees are recorded as male or female. Given that they are both categorical (binary) variables, we produce a cross-tabulation to assess whether they are associated.
We know that 17.07% arrestees received a harsher treatment and 82.93% were released with a summons. If gender is not associated with police treatment (i.e., if the null hypothesis is true), we should expect roughly similar proportions among both males and females. If, however, proportions across male and female arrestees are different, that would serve as evidence that the two variables could be associated.
Let’s have a look at the cross-tabulation.
# produce a cross-tabulation between 'sex' and 'released'
tbl_cross(data = Arrests, row = sex, col = released, percent = "row")|
released
|
Total | ||
|---|---|---|---|
| No | Yes | ||
| sex | |||
| Female | 63 (14%) | 380 (86%) | 443 (100%) |
| Male | 829 (17%) | 3,954 (83%) | 4,783 (100%) |
| Total | 892 (17%) | 4,334 (83%) | 5,226 (100%) |
The table indicates that 17% of male arrestees and 14% of female arrestees received harsher treatment, while 83% of male arrestees and 86% of female arrestees were released with a summons. These numbers are very similar and approximately follow the overall tendencies of arrestees who were (83%) and who were not released with a summons (17%). This suggests that gender does not seem to be associated with police treatment.
8.2 Regression modelling: why not linear regression?
Ok, great. If we have two categorical variables, we can produce a cross-tabulation. This cross-tabulation can be helpful in providing evidence for or against the hypothesis that those two variables are associated with each other.
But what if the independent variable is numerical? Or, what if we have more than one independent variable? Or, what if we need to control for a third common factor to remove confounding bias? Or, what if we have two independent variables whose effects on the dependent variable are conditional upon each other? We spent three weeks studying linear regression models. When the dependent variable is numerical, we already know how to handle all these scenarios. Now, we need to handle these scenarios when the dependent variable is not numerical as well.
Can’t we simply fit linear regression models with categorical dependent variables?
No. Rather, the short answer is no. The long answer is… sometimes. When the dependent variable is binary, in some circumstances, we can fit a linear regression model—these are called linear probability models. But that’s beyond our scope this semester. As far as this course unit goes, let’s stick to the short answer: no, we cannot.
The reason why we cannot fit linear regression models with categorical dependent variables is simple: this violates some of the key assumptions in linear regression models. All assumptions somehow get back to the fact that the dependent variable is numerical and as close as possible to normally distributed. If the dependent variable is categorical, there is not much we can do…
…in terms of linear regression. But there are other types of regression models! One of them, logistic regression models, was designed specifically to handle categorical binary variables. That’s our focus now! We have binomial logistic regression models for binary dependent variables, ordinal logistic regression models for ordinal dependent variables, and multinomial logistic regression models for nominal (unordered) dependent variables. In this course unit, we are only going to learn about binomial logistic regression models—when the dependent variable is binary. Other types of categorical dependent variables will, unfortunately, not be covered this semester.
Now, let’s see how we can adapt everything we know about linear regression models!
8.3 Logistic regression
In previous sessions, we covered linear regression models, which can be used to model variation in a numerical response variable. Here, we introduce logistic regression, a technique you may use when your dependent variable is binary—i.e., categorical and has two possible levels.
In criminology, very often, you will be interested in binary outcomes—e.g., we might want to investigate why some people have been stopped by the police whereas others have not; or why some people have been victimised while others have not; or why some people engage in criminal conduct while others do not, etc.—and want to use a number of independent variables to study these outcomes. It is, then, helpful to understand how to use these models. Logistic regression is part of a broader family of models called generalised linear models—it’s essentially a technical expansion of linear regression models for dependent variables that are not numerical and do not follow a normal distribution. You should read the Wikipedia entry for this concept here.
With logistic regression, we model the probability of belonging to one of the levels in the binary outcome. For any combination of values for our independent variables, the model estimates the probability of presenting the outcome of interest. The mathematics behind this estimation is beyond the scope of our course unit; it suffices to say that while linear regression coefficients are estimated using ordinary least squares (see Chapter 6), logistic regression coefficients are estimated using maximum likelihood—one of the most important estimators in statistics.
In logistic regression, we also start with a model in which variables of interest (e.g., \(Y, X_1, X_2, ...\)) are related to each other based on parameters that we need to estimate (e.g., \(\alpha, \beta_1, \beta_2, ...\)). Remember what the linear model looks like:
\[ Y = \alpha + \beta_1 \cdot X_1 + \beta_2 \cdot X_2 + ... + \beta_n\cdot X_n \] With logistic regression, we want to estimate a similar model. The right-hand side will remain unchanged: a combination of independent variables influencing the outcome based on estimated \(\beta\) coefficients. However, the left-hand side of the equation does not work anymore. Because the dependent variable is now binary, the left-hand side of this linear model is no longer appropriate. If \(Y\) is binary, that means that it can only have two values—e.g., 0 or 1. To avoid confusion and ensure that we know that this is a binary variable, let’s call it \(p\) when \(y=1\) and \(1-p\) when \(y=0\). If we were to simply estimate a linear model with a binary dependent variable, then this linear equation could end up yielding all sorts of values of \(Y\)—values that are not 0 or 1.10
The logistic regression model solves this issue by modelling the odds of an event occurring. Unlike linear models, which directly model the dependent variable, logistic regression focuses on the ratio \(\frac{p}{1-p}\), known as odds. If you are familiar with betting, you may already know a thing or two about odds. Odds represent how much more likely an event is to happen than not to happen.
Let’s go back to our example: marijuana-possession arrestees in Toronto. We know, from above, that most arrestees are released with a summons. Let’s remember the numbers:
##
## No Yes
## 892 4334So, we know that \(p=\) 4334 arrestees were released with a summons and that \(1-p=\) 892 received a harsher treatment. If we want to calculate the odds of being released with a summons, we simply need to calculate the ratio \(\frac{p}{1-p}=\frac{4334}{892}\). In this case, the odds are 4.86, which means that being released with a summons is 4.86 times more likely to occur than receiving harsher treatment.
Our goal will be to treat these odds as our main target! Is the colour of the arrestee associated with increases or decreases in the odds of being released with a summons? What about citizenship status? Is it associated with increases or decreases in the odds of being released with a summons? Going back to the linear model above, we are going to put the odds of an event occurring in the left-hand side of the equation!
Unfortunately, for a bunch of mathematical reasons that we don’t need to worry about for now, we cannot simply put the odds \(\frac{p}{1-p}\) in the left-hand side of the equation. Instead, we need to put the natural logarithm of the odds in the left-hand side of the equation:
\[ log \bigg( \frac{p}{1-p} \bigg) = \alpha + \beta_1 \cdot X_1 + \beta_2 \cdot X_2 + ... + \beta_n\cdot X_n \] Don’t worry about that logarithm in the equation. We will get rid of it soon. For now, what we can see is that the right-hand side of the equation remains unchanged, and the left-hand side of the equation includes some stuff that we still don’t know how to interpret. Let’s give a name for the stuff on the left-hand side of the equation: let’s call it logit. The logit of a binary variable is the natural logarithm of the odds of the event occurring. That’s why this model is called logistic regression!
But because the right-hand side of the equation remains unchanged, so will our interpretation! For instance, we can simply say that a one-unit increase in \(X_1\) is associated with a \(\beta_1\)-increase in the log-odds of \(Y\). The same applies to binary independent variables, categorical independent variables, multiple regression models, and interactions—everything that we learned about interpreting linear regression models applies here, as long we remember that everything refers to the log-odds of the dependent variable.
So, that’s great! Or almost… there’s only one problem: what does an increase or decrease in the log-odds of a variable even mean? Interpreting the log odds scale is something some people do not find very intuitive. To make things more intuitive, we need to get rid of the logarithm and get back to odds! After all, what we want to know is the extent to which independent variables are associated with increases or decreases in the odds of an event occurring.
How do we get rid of the log-odds scale? By exponentiating coefficients!
Don’t remember logarithms? Don’t worry! Click here for a quick refresher
A logarithm is the inverse operation of exponentiation, meaning it undoes the effect of raising a number to a power. If we have an equation like \(a^b = c\), the logarithm allows us to solve for \(b\) by rewriting it as \(\log_a(c) = b\). In other words, the logarithm tells us what exponent we need to raise the base \(a\) to in order to get \(c\). For example, since \(2^3 = 8\), it follows that \(\log_2(8) = 3\).
This inverse relationship is similar to how subtraction undoes addition or how division undoes multiplication. Logarithms are particularly useful in mathematics and science for handling exponential growth or decay, compressing large numbers into manageable scales, and solving equations where the exponent is the unknown. The most common logarithms are base 10 (common logarithm, \(\log\)), base \(e\) (natural logarithm, \(\ln\)), and base 2 (binary logarithm, used in computing).
In logistic regression, we use the natural logarithm—base \(e\). Therefore, to get rid of the log-odds scale, we simply exponentiate coefficients: \(e^{\beta_1}\), which we can obtain using the R function exp().
If we simply exponentiate the regression coefficients (e.g., \(e^{\beta_1}\), which we can obtain using the R function exp()), we get rid of the log-odds scale and obtain what we call odds ratios. Using odds ratios when interpreting logistic regression coefficients is very common. The key word to remember here is multiplies.
Interpreting logistic regression coefficients as odds ratios
A one-unit increase in \(X_1\) multiplies the odds of the event \(Y\) occurring by \(exp^{\beta_1}\)
Odds ratios, by definition, will always be greater than 0. Multiplying something by a number between 0 and 1 actually reduces the number: for example, if we multiply 10 by 0.4, the result is 4, a decrease of 60%. If we multiply something by 1, it stays the same: for example, if we multiply 10 by 1, the result is 10. If we multiply something by a number greater than 1, it implies an increase: for example, if we multiply 10 by 1.5, the result is 15, an increase of 50%.
- An estimated odds ratio (\(exp^{\beta}\)) between 0 and 1 implies a negative association
- An estimated odds ratio (\(exp^{\beta}\)) equal to 1 implies no association
- An estimated odds ratio (\(exp^{\beta}\)) greater than 1 implies a positive association
Let’s practice all that, seeking to understand what factors are associated with greater or lower odds of marijuana-possession arrestees being released with a summons!
8.4 Fitting logistic regression
It is fairly straightforward to run a logistic model. Assuming that the dependent variable is binary, we can use the glm() function in R. It works exactly the same way as the lm() function—we only need to specify that we will be using a logit function link (we can do that by including the argument family = binomial).
glm(dependent_var ~ independent_var1 + independent_var2 + independent_var3, data = dataset, family = binomial)Now, let’s fit a multiple logistic regression. The dependent variable, as before, indicates whether arrestees were released with a summons or not. To ensure that we are modeling the odds of being released with a summons (and not the odds of receiving harsher treatment), we recoded the released variable so that “Yes” (released) is coded as 1 and “No” (not released) is coded as 0.
In logistic regression, the event coded as 1 is the comparison group (the outcome for which we are modeling the odds), and the group coded as 0 serves as the reference category.
# load the dplyr package
library(dplyr)
# recode the 'released' variable to ensure that the
# comparison group is coded as 1
Arrests <- mutate(Arrests,
released = case_when(
released == "Yes" ~ 1,
released == "No" ~ 0
))Now we can fit the multiple logistic regression. As independent variables, let’s include arrestees’ racial identity (colour), gender (sex), the number of entries in the criminal justice system (checks), and whether they were employed at the time of arrest (employed).
# Fit a logistic regression model and store it under 'logistic_reg'
logistic_reg <- glm(released ~ colour + sex + checks + employed, data = Arrests, family = binomial)
# print the estimated coefficients
logistic_reg##
## Call: glm(formula = released ~ colour + sex + checks + employed, family = binomial,
## data = Arrests)
##
## Coefficients:
## (Intercept) colourWhite sexMale checks employedYes
## 1.40739 0.49608 -0.04215 -0.35796 0.77973
##
## Degrees of Freedom: 5225 Total (i.e. Null); 5221 Residual
## Null Deviance: 4776
## Residual Deviance: 4331 AIC: 4341The table, as you will see, is similar to the one you get when running linear regression. For now, we can ignore the new information at the very bottom of the output (these are fit indices, including the null and deviance residuals and the Akaike Information Criteria—AIC). Let’s focus on the estimated coefficients. We could rewrite the logit equation with the estimated parameters now:
\[ log \bigg( \frac{release\_summons}{harsher\_treatment} \bigg) = 1.407 + 0.496\cdot colour - 0.042\cdot sex - 0.358\cdot checks + 0.780\cdot employed \]
Based on this, we can conclude that White arrestees’ log-odds of being released with a summons are \(\beta_1=0.496\) larger than Black arrestees’ log-odds, controlling for sex, previous checks in the criminal justice system, and employment status; that male’s log-odds of being released are \(\beta_2=-0.042\) lower than females’, controlling for race, previous checks in the criminal justice system, and employment status; that every additional check in the criminal justice system is associated with a decrease of \(\beta_3=-0.358\) in the log-odds of being released, controlling for race, sex, and employment status; and that employed arrestees’ log-odds are \(\beta_4=0.780\) larger than the log-odds among unemployed arrestees, controlling for race, sex, and checks in the criminal justice system.
So what does that actually mean? As mentioned above, interpreting the log odds scale is something some people do not find very intuitive. So, using odd ratios when interpreting logistic regression is common. To do this, all we need to do is to exponentiate the coefficients. To get the exponentiated coefficients, you tell R that you want to exponentiate (exp()), that the object you want to exponentiate is called coefficients, and it is part of the model you just ran. We can do this in several steps or in one step.
# store regression coefficients under 'coefficients'
coefficients <- coef(logistic_reg)
# exponentiate all coefficients to obtain odds ratios
exp(coefficients)## (Intercept) colourWhite sexMale checks employedYes
## 4.0852619 1.6422658 0.9587242 0.6990998 2.1808765Much better! Now that we have exponentiated the coefficients, we have odds ratios—, which are much easier to interpret than coefficients on the log-odds scale.
- White arrestees’ odds of being released with a summons are 64% higher than Black arrestees’ odds of being released with a summons, controlling for sex, checks in the criminal justice system, and employment status.
- i.e., being White multiplies the odds of release with a summons by 1.64.
- Male arrestees’ odds of being released with a summons are 4.13% lower than female arrestees’ odds of being released with a summons, controlling for race, checks in the criminal justice system, and employment status.
- i.e., being male multiplies the odds of release with a summons by 0.96.
- Every additional check in the criminal justice system is associated with a decrease of 30.1% in the odds of being released with a summons, controlling for race, sex, and employment status
- i.e., every additional check in the criminal justice system multiplies the odds of being released with a summons by 0.70.
- Employed arrestees’ odds of being released with a summons are more than twice as high as unemployed arrestees’ odds of being released with a summons, controlling for race, sex, and employment status.
- i.e., being employed multiplies the odds of release with a summons by 2.18.
For more details on interpreting odd ratios in logistic regression, you may want to read this. Some people do not like odd ratios. For other ways of interpreting logistic regression coefficients, you may want to consult chapter 5 of the book by Gelman and Hill (2007).
You can read more about how to interpret odd ratios in logistic regression here.
See the appendix for an alternative way of getting the same results with less typing.
As with linear regression, the interpretation of regression coefficients is sensitive to the scale of measurement of the predictors. This means one cannot compare the magnitude of the coefficients to compare the relevance of variables to predict the response variable. The same applies to the odd ratios. Tempting and common as this might be, unless the independent variables use the same metric (or maybe if they are all categorical), there is little point in comparing the magnitude of the odd ratios in logistic regression. Like the unstandardised logistic regression coefficients, odd ratios are not a measure of effect size that allows comparisons across inputs (Menard, 2012).
We can also produce effect plots using the effects package:
# load the 'effects' package
library(effects)
# produce effect plots
plot(allEffects(logistic_reg), ask = FALSE)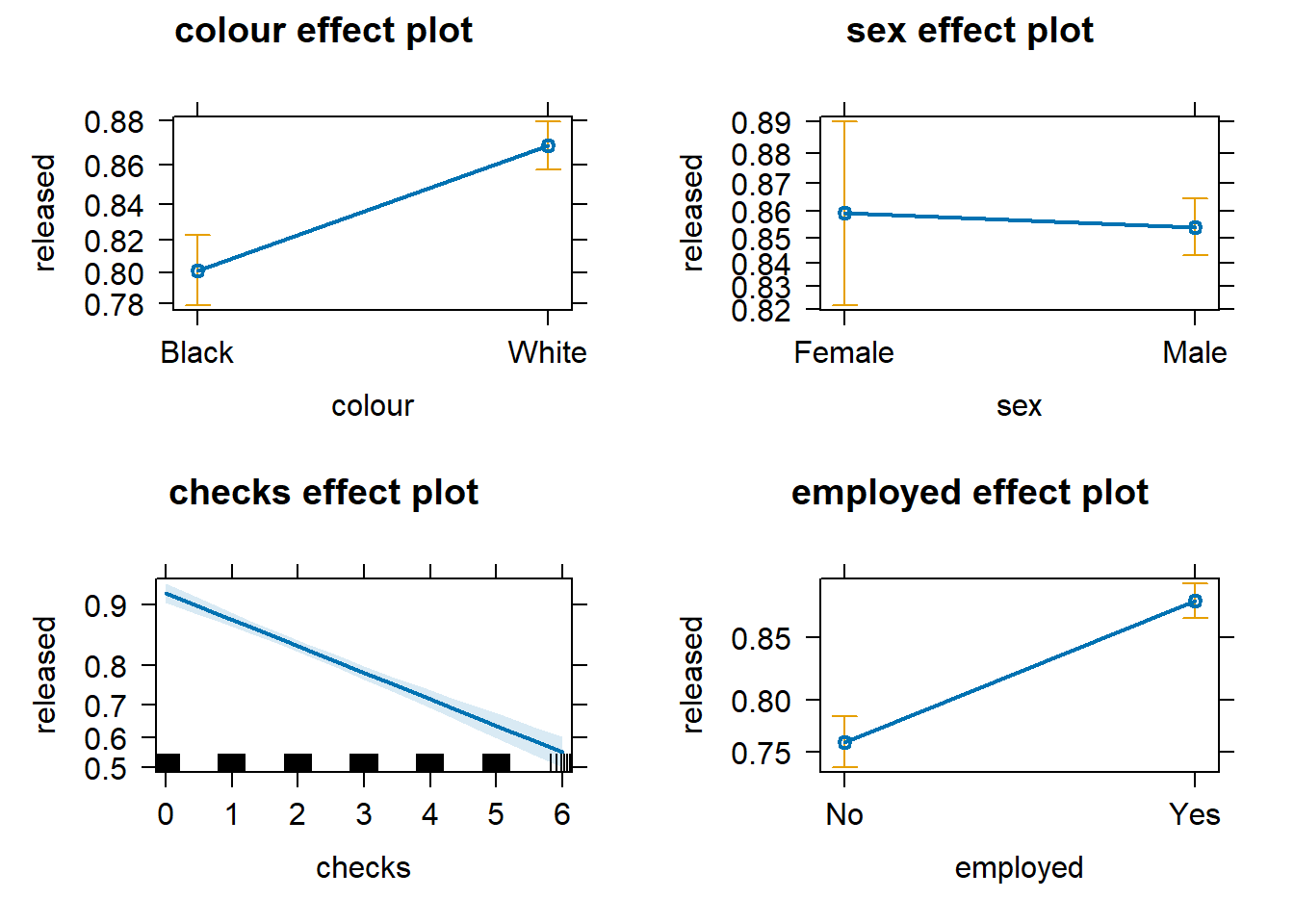
Effect plots in this context are particularly helpful because they summarise the results using probabilities, which is what you see plotted on the y-axis.
We don’t have to print them all. When we are primarily concerned with one of them, as in this case, that’s the one we want to emphasise when presenting and discussing our results. There isn’t much point in discussing the results for the variables we simply defined as control (given what our research goal was). So, in this case, we would ask for the plot for our input measuring race/ethnicity:
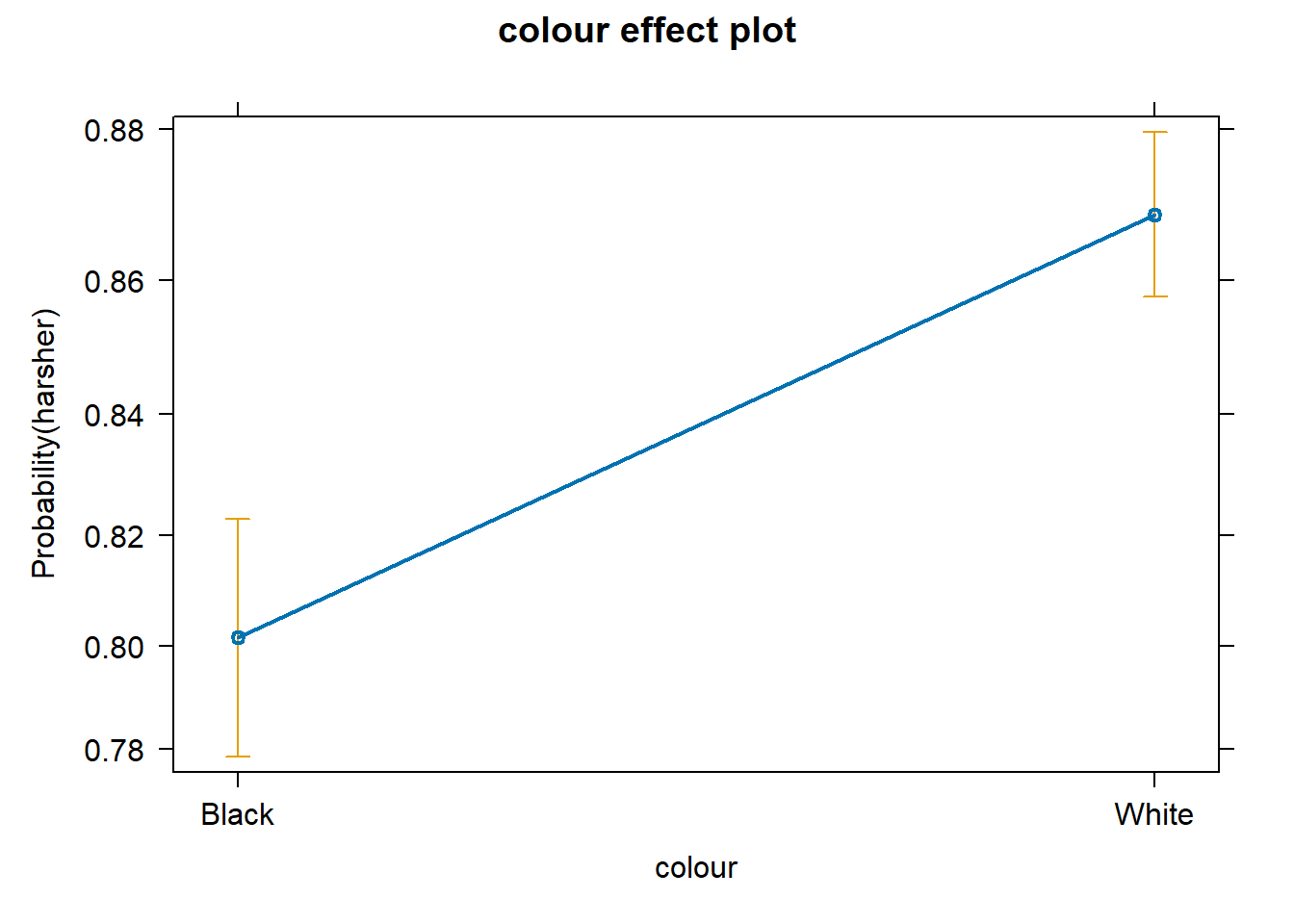
We can use the predict() function to generate the predicted probability that the arrestees will be released given what we know about their inputs in the model, given values of the predictors. By default, R will compute the probabilities for the dataset we fitted the model with. Here, we have printed only the first ten probabilities, but the way we use the predict() function here will generate a predicted probability for each case in the dataset.
logistic_reg_prob <- predict(logistic_reg, type = "response") #If you want to add this to your dataframe, you could designate your object as Arrests$fitl_1_prob
logistic_reg_prob[1:10]## 1 2 3 4 5 6 7 8
## 0.8273773 0.7448014 0.8273773 0.8565590 0.8616606 0.8990862 0.8654497 0.9109450
## 9 10
## 0.6710889 0.8273773It is important to understand that with this type of model, we usually generate two types of predictions. On the one hand, we are producing a continuous valued prediction in the form of a probability, but we can also generate a predicted class for each case. In many applied settings, the latter will be relevant. A discrete category prediction may be required in order to make a decision. Imagine a probation officer evaluating the future risk of a client. She/He would want to know whether the case is high risk or not.
8.5 Interactions
The data we have been using were obtained by the author of the effects package from Michael Friendly, another prominent contributor to the development of R packages. The data are related to a series of stories revealed by the Toronto Star and further analysed by Professor Friendly as seen here. In this further analysis, Friendly proposes a slightly more complex model than the one we have specified so far. This model adds three new predictors (citizenship, age, and year in which the case was processed) and also allows for interactions between race (colour) and year, as well as race and age.
# fit new multiple logistic regression
logistic_reg_2 <- glm(released ~ employed + citizen + checks + colour * year + colour * age,
family = binomial, data = Arrests)
# print results
logistic_reg_2##
## Call: glm(formula = released ~ employed + citizen + checks + colour *
## year + colour * age, family = binomial, data = Arrests)
##
## Coefficients:
## (Intercept) employedYes citizenYes checks
## -227.48053 0.74748 0.62016 -0.36472
## colourWhite year age colourWhite:year
## 361.66832 0.11391 0.02879 -0.18022
## colourWhite:age
## -0.03813
##
## Degrees of Freedom: 5225 Total (i.e. Null); 5217 Residual
## Null Deviance: 4776
## Residual Deviance: 4275 AIC: 4293What we see here is that the two interactions included are somewhat different from 0. To assist in the interpretation of interactions, it is helpful to look at effect plots.
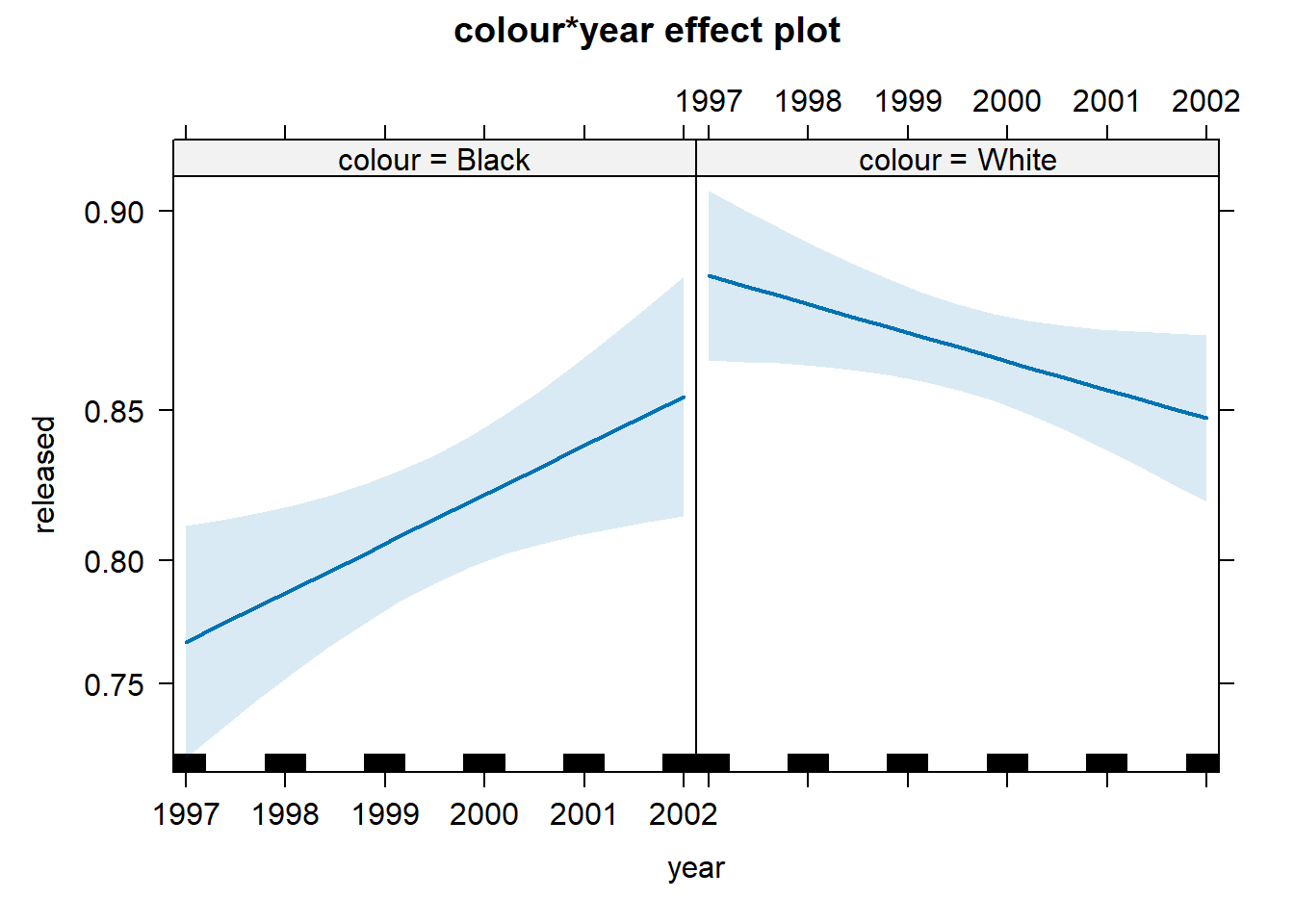
First, we see that up to 2000, there is strong evidence for differential treatment of blacks and whites. However, we also see evidence to support Police claims of the effect of training to reduce racial effects.
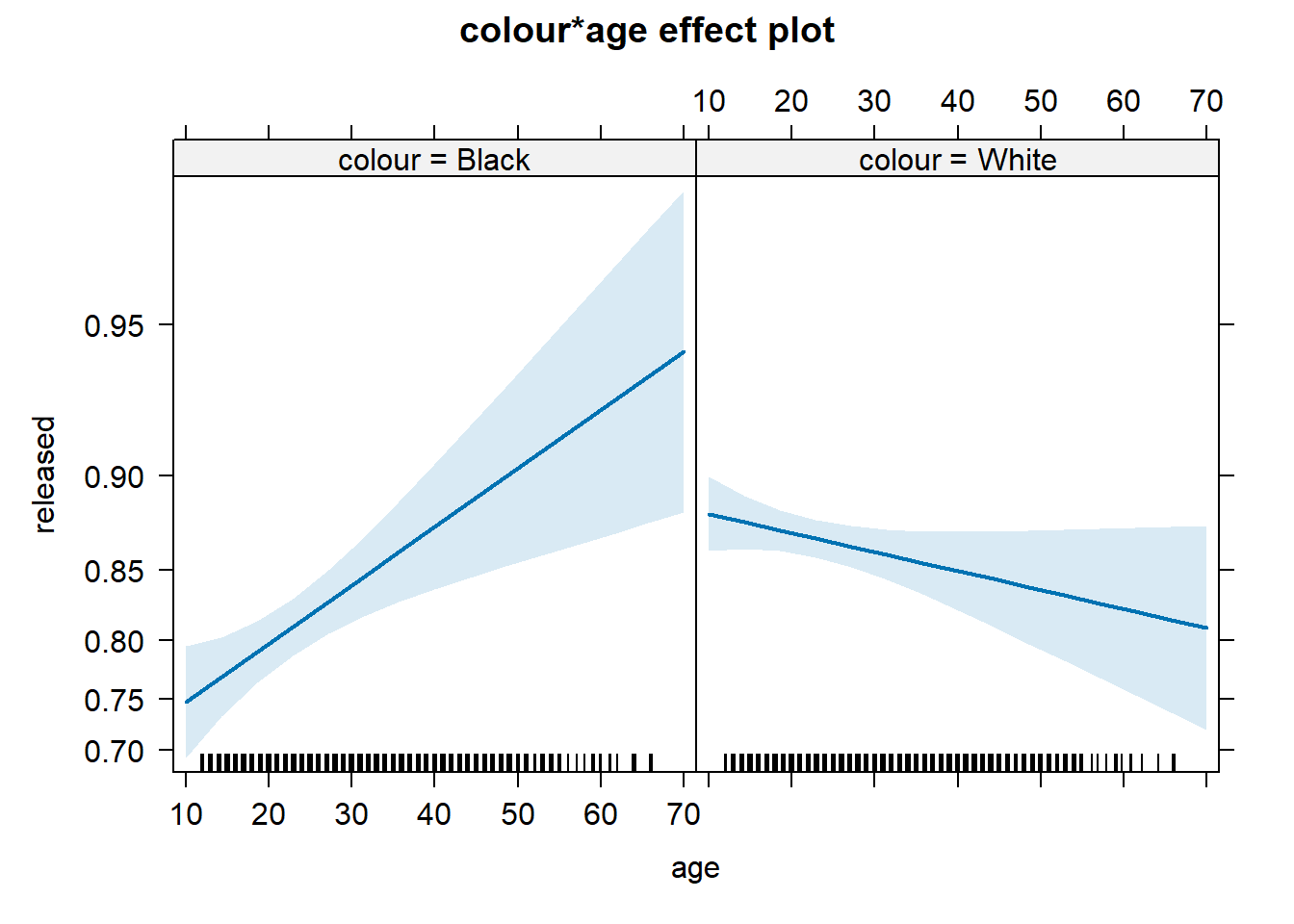
On the other hand, we see a significant interaction between race and age. Young blacks are treated more harshly than young whites. However, older blacks were treated less harshly than older whites.
In a previous session, we discussed the difficulties of interpreting regression coefficients in models with interactions. Centring and standardising in the way discussed earlier can actually be of help for this purpose.
8.6 Assessing model fit: confusion matrix
If we are interested in “qualitative” prediction, we also need to consider other measures of fit. In many applied settings, such as in applied predictive modelling, this can be the case. Imagine you are developing a tool to be used to forecast the probability of repeat victimisation in cases of domestic violence. This type of prediction may then be used to determine the type of police response to cases defined as high-risk. Clearly, you want to make sure the classification you make is as accurate as possible.
In these contexts, it is common to start from a classification table or confusion matrix. A confusion matrix is simply a cross-tabulation of the observed outcome in relation to the predicted outcome. We saw earlier how the predict() function generated a set of predicted probabilities for each of the subjects in the study. To produce a classification table in this context, we must define a cut-off point, a particular probability that we will use to classify cases. We will define anybody above that cut-off as belonging to the level of interest and anybody below we will define as not. We could, for example, say that anybody with a probability larger than .5 should be predicted to receive harsher treatment.
The confusion matrix typically follows this layout:
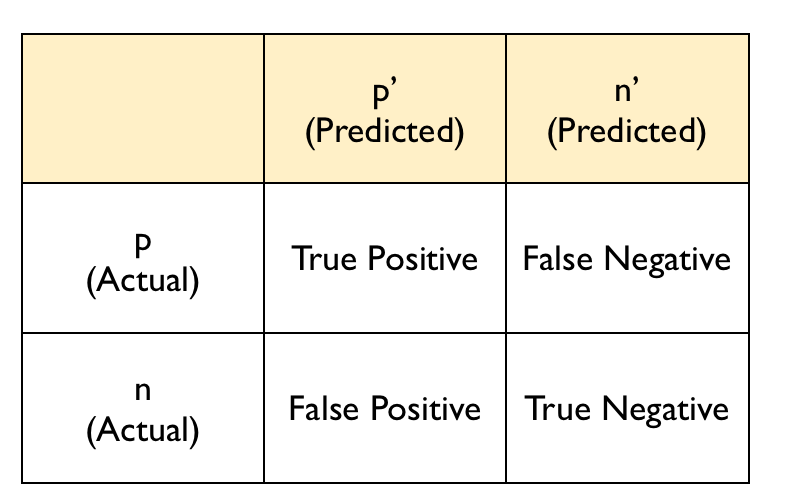
The diagonal entries correspond to observations that are classified correctly according to our model and our cut-off point, whereas the off-diagonal entries are misclassifications. False negatives are observations that were classified as zeros but turned out to be ones (the outcome of interest). False positives are observations that were classified as ones (the outcome of interest) but turned out to be zeros.
There are various ways of producing a confusion matrix in R. The most basic one is to ask for the cross-tabulation of the predicted classes (determined by the cut-off criterion) versus the observed classes.
#to create a confusion matrix, we want
#our variable to be back to a factor
Arrests <- mutate(Arrests,
released = case_when(
released == 1 ~ "Yes",
released == 0 ~ "No"
),
released = as.factor(released))
#First, we define the classes according to the cut-off
logistic_reg_pred_class <- logistic_reg_prob > .5
#This creates a logical vector that returns TRUE
#when the condition is met (the subject is predicted to be released) and
#FALSE when the condition is not met (the subject is not released)
logistic_reg_pred_class[1:10]## 1 2 3 4 5 6 7 8 9 10
## TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE#Let's make this into a factor with the same levels as the original variable
released_pred <- as.factor(logistic_reg_pred_class)
levels(released_pred) <- c("No","Yes")
table(released_pred)## released_pred
## No Yes
## 113 5113##
## released_pred No Yes
## No 57 56
## Yes 835 4278What does this tell us? Well, we can see how our predictions about release compare to what was actually observed. The sum of the table is just the number of our predictions (5226), which is the same as the number of rows in our data frame. A broad summary would be to calculate how many predictions we got wrong, namely, 891 (835 + 56) and then calculate the proportion of that given all the predictions made, namely, 891/5226 = 17%. So, based on the 0.5 threshold decided earlier, we’d conclude that we got 17% wrong and therefore had an accuracy of 83%.
Extra stuff about classification tables
We can derive various useful measures from classification tables. Two important ones are the sensitivity and the specificity. The model’s sensitivity is the rate at which the event of interest (e.g., being released) is predicted correctly for all cases having the event.
Sensitivity = number of cases with the event and predicted to have the event/number of samples actually presenting the event
In this case, this amounts to 4278 divided by 56 plus 4278. The sensitivity is sometimes also considered the true positive rate since it measures the accuracy in the event population. On the other hand, specificity is defined as:
Specificity = number of cases without the events and predicted as non-events/number of cases without the event
In this case, this amounts to 57 divided by 57 plus 835. The false positive rate is defined as one minus the specificity.
We can generate these measures automatically from the table we produced. However, for this sort of thing, I prefer to use the confusionMatrix() function from the caret package. It produces a very detailed set of calibration measures that help indicate how well the model is classifying.
## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 57 56
## Yes 835 4278
##
## Accuracy : 0.8295
## 95% CI : (0.819, 0.8396)
## No Information Rate : 0.8293
## P-Value [Acc > NIR] : 0.4943
##
## Kappa : 0.078
##
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.9871
## Specificity : 0.0639
## Pos Pred Value : 0.8367
## Neg Pred Value : 0.5044
## Prevalence : 0.8293
## Detection Rate : 0.8186
## Detection Prevalence : 0.9784
## Balanced Accuracy : 0.5255
##
## 'Positive' Class : Yes
## #The data argument specifies the vector
#with the predictions and the reference
#argument the vector with the observed
#outcome or event. The positive argument
#identifies the level of interest in the factor.We can see first the accuracy. The overall accuracy rate gives us the agreement between the observed and predicted classes. However, the overall accuracy is often not the most useful measure. Kappa is also a measure that is often used with values ranging between 0.30 and 0.50 considered to indicate reasonable agreement. However, for many applications, it will be of interest to focus on the sensitivity and the specificity as defined above. In this case, we can see that our sensitivity, or the true positive rate, is good. However, our Kappa is not. The model can predict those who are released with summons but is not doing so well predicting harsh treatment with the selected cut-off point.
One of the problems with taking this approach is that the choice of the cut-off point can be arbitrary, and yet this cut-off point will impact the sensitivity and specificity of the model. There is a trade-off between sensitivity and specificity. Given a fixed accuracy, more of one will result in less of the other.
So if we use a different cut-off point, say .75, the classification table would look like this. Note that to do this, we create our own function called precision – the R code itself is much more advanced that this course, so don’t worry too much about that. It’s a demonstration of calculating specificity and sensitivity.
precision<-function(c) {
tab1 <- table(logistic_reg_prob>c, Arrests$released)
out <- diag(tab1)/apply(tab1, 2, sum)
names(out) <- c('specificity', 'sensitivity')
list(tab1, out)
}
precision(.75)## [[1]]
##
## No Yes
## FALSE 396 707
## TRUE 496 3627
##
## [[2]]
## specificity sensitivity
## 0.4439462 0.8368713Here, we are predicting, according to our model, that anybody with a probability above .75 will be released with summons. Our sensitivity decreases, but our specificity goes up. You can see that the cut-off point will affect how many false positives and false negatives we have. The overall accuracy is still the same, but we have shifted the balance between sensitivity and specificity.
Potential trade-offs here may be appropriate when there are different penalties or costs associated with each type of error. For example, if you are trying to predict a homicide as part of an intervention or prevention program, you may give more importance to not making a false negative error. That is, you want to identify as many potential homicide victims as possible, even if that means that you will identify as victims individuals that, in the end, won’t be (false positives). On the other hand, if you have limited resources to attend to all the cases that you will predict as positives, you also need to factor this into the equation. You don’t want to use a cut-off point that will lead you to identify more cases as potential homicide victims than you can possibly work with.
Similarly, the criminal justice system is essentially built around the idea of avoiding false positives - that is, convicting people who are innocent. You will have heard many phrases like “innocent until proven guilty” or “It is far better that 10 guilty men go free than one innocent man is wrongfully convicted”. This approach would incline us to err on the side of false negatives and avoid false positives (higher sensitivity, lower specificity).
We may want to see what happens to sensitivity and specificity for different cut-off points. For this, we can look at receiver operating characteristics or simply ROC curves. This is essentially a tool for evaluating the sensitivity/specificity trade-off. The ROC curve can be used to investigate alternate cut-offs for class probabilities. See the appendix for more info on the ROC curve. There are also other ways to assess a model’s fit, such as deviance and pseudo r squared. For those interested, you can read more in the appendix.–>
8.7 Lab Exercises
Your turn! In the lab session, answer the following questions. Note that not all questions necessarily require analysing data in R. After you finish, click on ‘Reveal answer!’ to check your answers.
We start by revisiting the ‘Ban the Box: fair chance recruitment’ practices in the UK, a dataset from Week 2. We first load, select the needed variables, and carry out any data transformation required.
library(haven)
banbox <- read_dta("https://dataverse.harvard.edu/api/access/datafile/3036350")
#if you have issues with loading the data
#see section 2.2 on how to get the data
#select needed variables
banbox <- banbox %>% select (response, black, crime, empgap)
#data transformation
banbox$black_f <- factor(banbox$black, levels = c(0, 1), labels = c("non-Black", "Black"))Using the above data, we want to assess whether receiving a positive answer to a job application is associated with having a criminal record. Your variables of interest are response - Application received Positive Response; empgap - Applicant has Employment Gap; crime - Applicant has Criminal Record; and black - whether someone is black or not.
- Based on your research hypothesis, what are your dependent and independent variables?
Reveal answer!
Dependent variable: Application received Positive Response, i.e., response.
Independent variable: Applicant has Criminal Record, i.e., crime.
- Is your dependent variable numerical or categorical? If categorical, is it binary, ordinal, or multinomial? What about the independent variable?
Reveal answer!
The dependent variable, Application received Positive Response (responce), is a binary variable.
The independent variable, Applicant has Criminal Record (crime), is also a binary variable.
- Using your dependent and independent variables, what is your null hypothesis?
Reveal answer!
Null hypothesis: There is no association between having a criminal record and receiving a callback (response). In other words, the odds of receiving a positive response are the same for applicants with criminal records and those without criminal records.- Examine the relationship between your dependent and your independent variable using the appropriate visualisation strategies
Reveal answer!
We can produce a bar chart to assess the relationship
# produce barchart
library(ggplot2)
ggplot(banbox, aes(x = as_factor(crime), fill = factor(response, levels = c(0, 1), labels = c("No", "Yes")))) +
geom_bar(position = "fill") +
labs(y = "Proportion", fill = "Response", x = "criminal record") +
theme_minimal()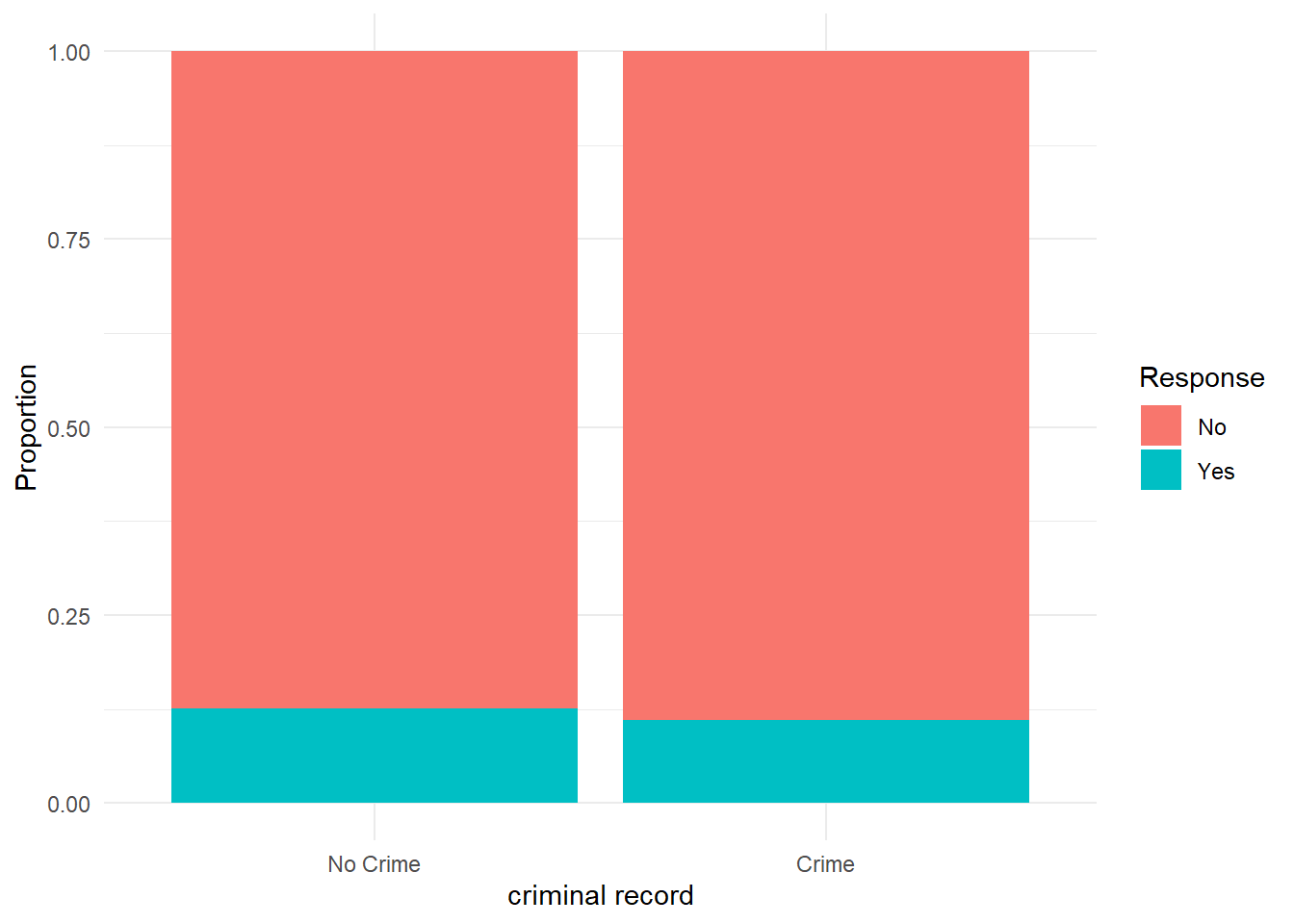
- Let’s build a logistic regression model. Replacing \(Y\) with the name of your dependent variable and \(X\) with the name of your independent variable, write down the equation with the unknown parameters (i.e, \(\alpha\) and \(\beta\)) that you want to estimate. Note: This question does not involve any data analysis.
Reveal answer!
\[ \log \left( \frac{P(\text{response} = 1)}{1 - P(\text{response} = 1)} \right) = \alpha + \beta \times \text{crime} \]
- Using the
glm()function, estimate the parameters of your logistic regression model. Rewrite the equation above by replacing unknown parameters with the estimated parameters.
Reveal answer!
# fit logistic regression model
log_reg <- glm(response ~ crime, data = banbox, family = binomial)
log_reg##
## Call: glm(formula = response ~ crime, family = binomial, data = banbox)
##
## Coefficients:
## (Intercept) crime
## -1.939 -0.149
##
## Degrees of Freedom: 14812 Total (i.e. Null); 14811 Residual
## Null Deviance: 10750
## Residual Deviance: 10740 AIC: 10740Based on the results of the linear regression model, we can rewrite the equation in the following way:
\[ \log \left( \frac{P(\text{response} = 1)}{1 - P(\text{response} = 1)} \right) = -1.939 + -0.149 \times \text{crime} \]
Applicants with a criminal record are less likely to receive a callback than applicants without a record.
- After fitting your logistic regression model to predict whether applicants receive a positive response (response), create a confusion matrix comparing predicted responses to actual responses. Use 0.5 as the cut-off point.
Reveal answer!
# fit regression model
log_reg_prob <- predict(log_reg, type = "response")
log_reg_pred_class <- log_reg_prob > .5
response_pred <- as.factor(log_reg_pred_class)
levels(response_pred) <- c("No","Yes")
banbox <- mutate(banbox,
response = case_when(
response == 1 ~ "Yes",
response == 0 ~ "No"
),
response = as.factor(response))
#Then we can produce the cross-tab
table(response_pred, banbox$response)##
## response_pred No Yes
## No 13066 1747
## Yes 0 0- What is the specificity of your logistic regression model predictions?
Reveal answer!
## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 13066 1747
## Yes 0 0
##
## Accuracy : 0.8821
## 95% CI : (0.8768, 0.8872)
## No Information Rate : 0.8821
## P-Value [Acc > NIR] : 0.5064
##
## Kappa : 0
##
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.0000
## Specificity : 1.0000
## Pos Pred Value : NaN
## Neg Pred Value : 0.8821
## Prevalence : 0.1179
## Detection Rate : 0.0000
## Detection Prevalence : 0.0000
## Balanced Accuracy : 0.5000
##
## 'Positive' Class : Yes
## A specificity of 1 means the model makes zero false positive errors — it never says “Yes” when the correct answer is “No.” Does this mean the model is a good one? Depends on what we are interested in predicting. Could other independent variables be added to the model?
8.8 Further resources
These are a set of useful external resources that may aid your comprehension (and I have partly relied upon myself, so credit to them!):
The UCLA guide to using logistic regression with R.
A helpful list of resources for general linear models with R.
If values were between 0 and 1, that wouldn’t be so problematic. Scores between 0 and 1 would simply be treated as estimated probabilities, which is what the linear probability model does. The problem is that the model can also yield scores greater than 1 and lower than 0, which are no longer interpretable as probabilities.↩︎